Kaggle Competition: Eedi – Mining Misconceptions in Mathematics
Math misconception prediction using embedding-based retrieval and LLM reranking — no model training required.
Period: Sep 2024 – Dec 2024
Project team:
- Pham Le Tu Nhi (Team leader)
- Nguyen Hoai An
- Phan Thao Nguyen
- Nguyen Dang Dang Khoa
- Huynh Cao Khoi
Role:
- Model developing
Overview
This project is the mid-term project for the course Deep learning for Data Science. Our team participated in the Eedi - Mining Misconceptions in Mathematics competition on Kaggle. The goal is to develop an Natural Language Processing (NLP) model driven by Machine Learning (ML) that accurately predicts the common misconceptions(distractors) behind incorrect answers for multiple-choice math questions.
My contributions
- Experimented with multiple embedding techniques, using both statistical methods and language models.
- Implemented a two-stage reranking pipeline to retrieve the top 25 most likely misconceptions for a given incorrect answer.
- Integrated multiple large language models (Qwen 2.5 14B & Qwen 2.5 32B) to enhance prediction performance.
Dataset
In a multiple-choice math question, we have four options (choices): one correct answer and three wrong ones (distractors). Each distractor captures a specific misconception. For example:
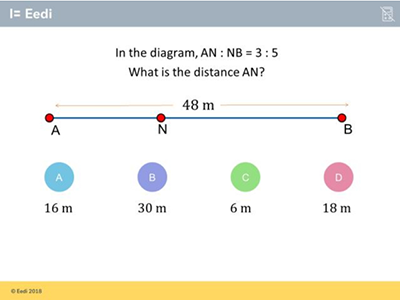
The correct answer is D) 18m, but if the students choose B) 30m, they might have the misconception about the wrong postion of a ratio equation.
So our dataset will be a complication of multiple choices questions, and the misconception also, which includes:
1. Multiple-choice question file
All question is stored in a csv file, each question(sample) includes the following key features:
- Construct: Most granular level of knowledge related to question.
- Subject: A broader context category than the construct.
- QuestionText: Question text extracted from the question image using human-in-the-loop OCR.
- CorrectAnswer: The correct choice of the question.
- Answer[A/B/C/D]Text: Answer option text extracted from the question image using human-in-the-loop OCR.
- Misconception[A/B/C/D]Id: Unique misconception identifier (int).
2. Misconception description file
A separate misconception reference table provides detailed text descriptions for each misconception.
So wrap-up, our task is: Given a question–incorrect answer pair, predict the misconception that led to that wrong answer
Approaches
We approached the problem with the two-phase pipline:
- Phase 01: Retrieval
- Phase 02: Re-ranking
The overall pipeline will look like this:
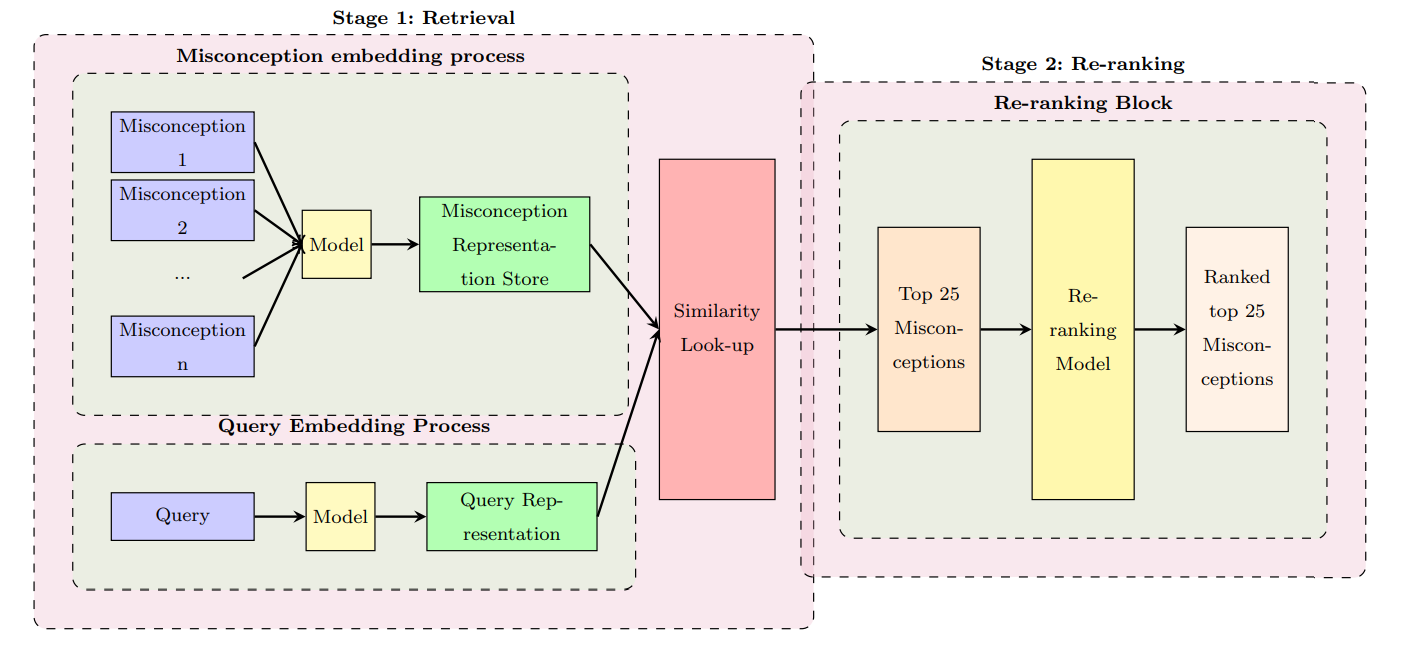
Then, we will explore each phase more.
Phase 1: Retrieval
This phase consists of three steps:
Step 1: Create embedding for question-wrong answer pair and misconceptions
For each question–wrong answer pair, we map it to a structured template containing the following information:
- Question
- Subject
- Construct
- Correct Answer
- Wrong Answer
This creates a rich, context-aware query for each pair, ready for embedding. We then use Qwen 2.5 14B to generate embeddings for both:
- All question–wrong answer pairs
- All misconception description
Step 2: Similarity Look-up
We apply a nearest neighbour algorithm to compute the similarity between each pair embedding and all misconception embeddings.
Step 3: Top-25 Retrieval
For each pair, we retrieve the top 25 most similar misconceptions as candidates for the next phase.
Phase 02: Re-ranking
We leverage the reasoning capability of a large language model to re-rank the 25 candidate misconceptions retrieved in Phase 1 into a more accurate order.
This phase has two key components:</p>
Qwen 2.5 32B Model
We use a structured prompt template to present the LLM with the question, the correct answer, the wrong answer, and the top-k candidate misconceptions, then ask it to select the most likely one, with this prompt
prompt = "You are an elite mathematics teacher tasked to assess the student's understanding of math concepts. Below, you will be presented with: the math question, the correct answer, the wrong answer and {k} possible misconceptions that could have led to the mistake.
{question_text}
Possible Misconceptions:{choices}
Select one misconception that leads to incorrect answer. Just output a single number
of your choice and nothing else.
Answer: "
Here, we can easily observe the conflict here, while the goal is to rerank top - k of misconception, but in the prompt, we just ask it to return just one most suitable, not the whole of re-rank order
This conflict will be explained with the second element: MultipleChoiceLogits
Multiple Choice Logits Processor
Multiple Choice Logits Processor can extract the raw token probabilities for each candidate misconception. By sorting the candidates according to these probabilities, we obtain a fully re-ranked list
From that, we can easily then sort the misconception base on their porbability, to get the new order or top - k.
The reason we want LLM just return one misconception, to reduce the cost of token, then, with Multiple Choice Logits Processor, we still achive the re-ranked order.
Some other approaches:
Conclusion
Overall, this project give me greate chance to learn more about NLP tasks, and how to apply the LLM to solve a problems in Kaggle.