Language Identification Model Evaluation – Part 01
A project that create a benchmark to evaluate multiple language identification models
Project period: Sep 2025 - Feb 2026
Project team:
- Mr.Hoan Nguyen (Superviser)
- Huynh Cao Khoi
Role:
- Data Collecting
- Data Preprocessing
- Exploratory Data Analysis (EDA)
- Model Evaluation
- Evaluation result analysis
Tools:
Hugging Face API, Polars, sentence_splitter, pyspark,unicodedata, semhash, cleanlab, Matplotlib, Seaborn, pytorch
Overview
This project was completed in my internship under the supervision of Mr.Hoan Nguyen.
The goal was to research and evaluate the current state of Language Identification (LID) — the task of detecting the language from a given text. LID is a fundamental component in many NLP pipelines, with many tasks such as machine translation, sentiment analysis, and multilingual text classification.
In this project, my main tasks were:
- Study about text datasets which are suitable for language identification task.
- Preprocess and combined multiple datasets into an evaluation benchmark.
- Perform exploratory data analysis (EDA) on the combined dataset.
- Evaluate models from this collection (combined with state-of-the-arts) in many metrics (even the runtime performance).
- Analyze and sumary the evaluation results.
Task 01: Collect text datasets
I surveyed a broad range of multilingual datasets, focus on those published mostly in recent years. The datasets include LID benchmarks , or datasets from other multilingual NLP tasks such as machine translation, sentiment analysis ,…
Finally, I have a collection ~20 datasets, covering a wide range of topics and domains. The full list of these datasets and their information can be found in this spreedsheet
The collected data follows this format:
| Language | Text |
|---|---|
| aeb_Arab | وفي ستينيات القرن الماضي، خدم بريجنسكي مستشار لجون إف كينيدي ومبعد خدم في إدارة ليندون جونسون. |
| ajp_Arab | ببعض البلاد الفيدرالية ، متل الولايات المتحدة وكندا ، بفرضو ضريبة الدخل على المستوى الفيدرالي وعلى ا… |
| bjn_Arab | كاچوالي ڤيان ديڤلومات ناڠ باݢاوي ديلوار ناݢري, با`ارتي ڤيان موستي مامبايار ڤاجاك ڤاڠهاسيلان دي ناݢار… |
Each sample contains two attributes:
- Language: The language code, normally follows the format
language_script, where: - Text: The raw text sample in the corresponding language and script.
Task 02: Merge and preprocess the combined text datasets
While downloading the dataset from multiple sources, I applied a simple preprocessing pipeline to each dataset before merging them together.
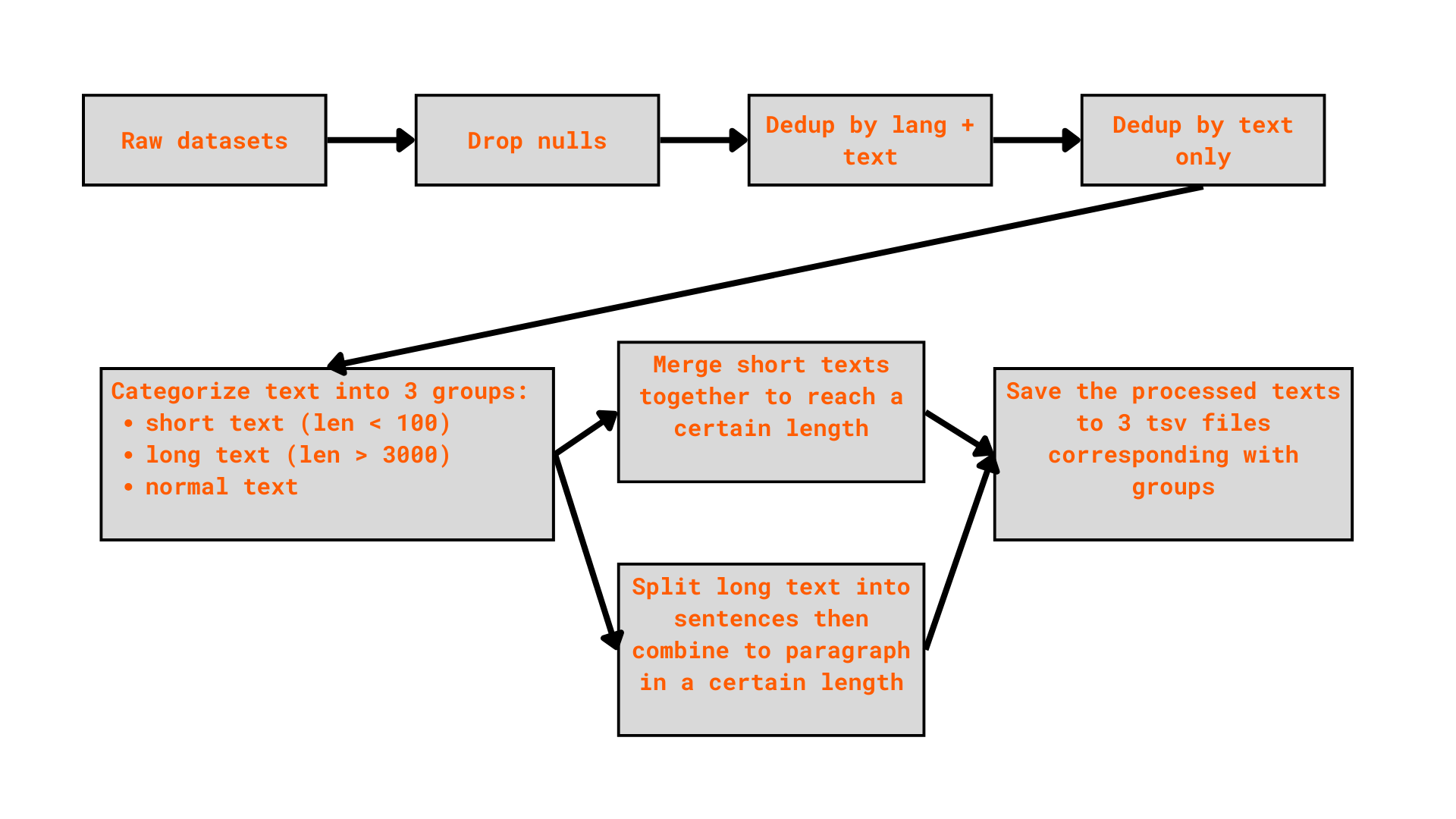
To handling long text, I used the sentence-splitter package to accurately split long texts into sentences, ensuring each sample has a manageable and consistent length for downstream evaluation.
Finally, I stored all the cleaned dataset in [this Kaggle collection][https://www.kaggle.com/work/collections/17790420]
After preprocessing all sources individually, I merged them all into a single unified dataset using the following pipeline:
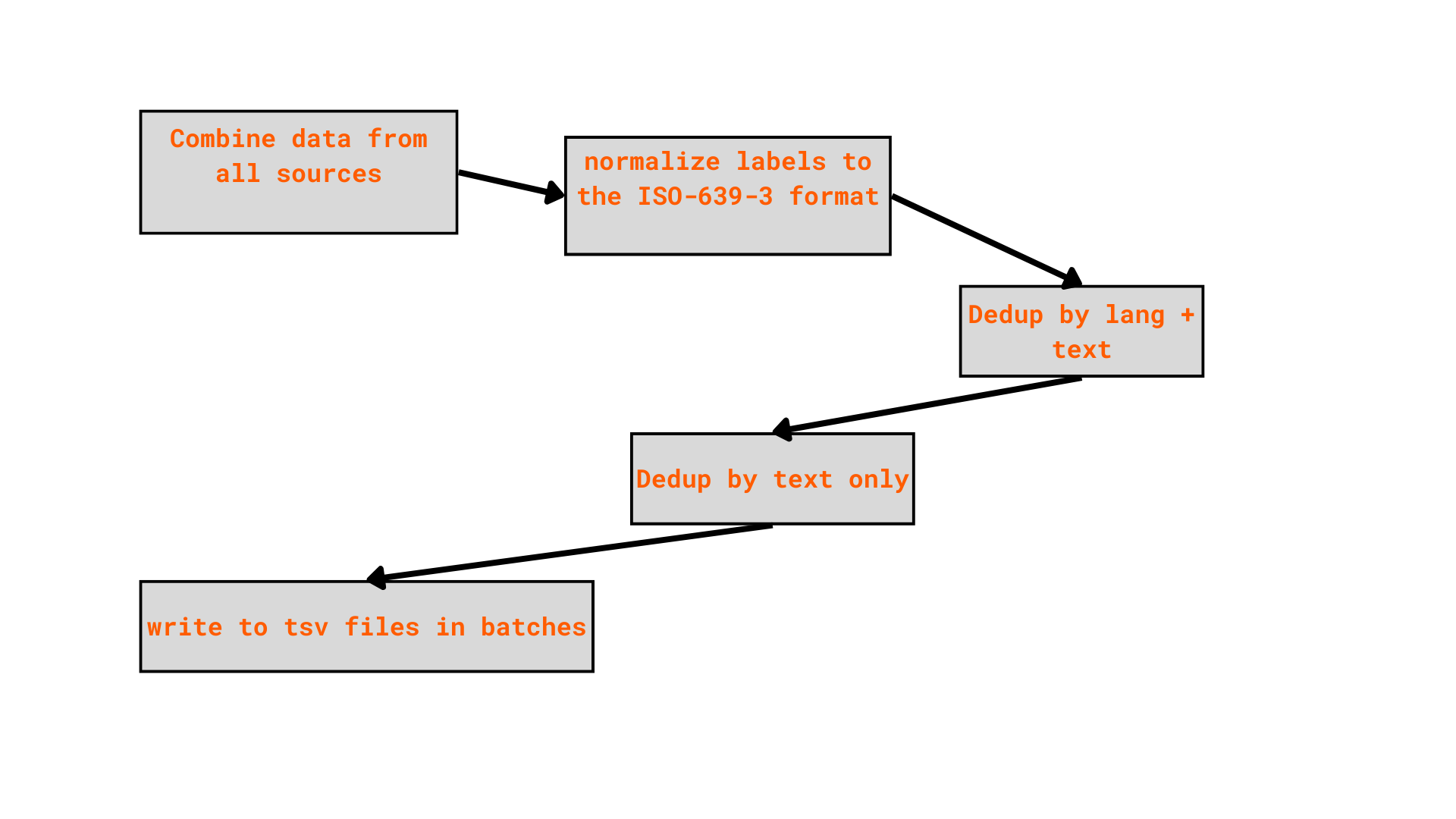
With the combined dataset, I applied these cleaning steps:
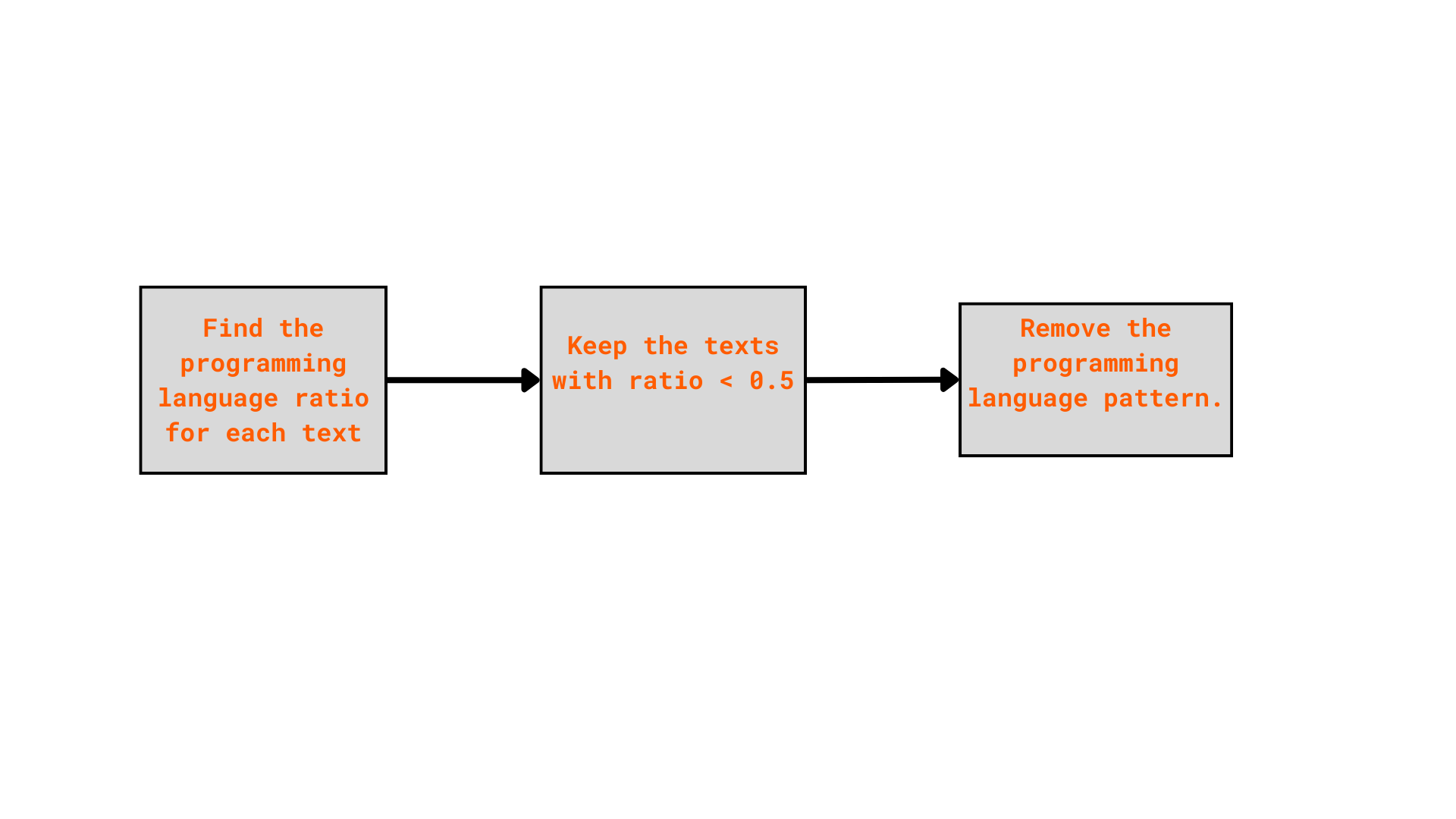
Step 01: Clean the programming language pattern
Programming language is not the natural language, I considered it as noise in a LID dataset. For example, I found some samples, which have the symbols or pattern which is more look like programming language in the combined dataset
| text | source | lang | code_ratio |
| _____________________________ | old_news | fra | 0.9959514 |
| ____________________________ | |||
| ________________________________________ ______________________________ | old_news | fra | 0.9930796 |
| ____________________________________ _________________________________ | old_news | fra | 0.9949495 |
| ________________________ | toxic_text | eng | 1.0 |
| // ************************* // | toxic_text | eng | 0.9746835 |
| +—————————————————————————+ | toxic_text | eng | 1.0 |
| <_>2.*2 <_>2 <_+>4 <_>2.*3 <_>4 <6> <6+> <_+>2. <_+>4 <6> <6+> <_> <_+>4. <6>8 <_>4 <4> <3> <_>2. <6>8. <6+>16 <_>4 <6+>8 <5> <_+>2 <_>8 <6> <_>4 <4> <3> <_+>2. <_!> <_> <_>2 <6>4... | toxic_text | fra | 0.520751 |
I simply used re package to find the programming language pattern inside the text. The text containing mostly programming language pattern will be removed. In others, I cleand all the possible patterns.
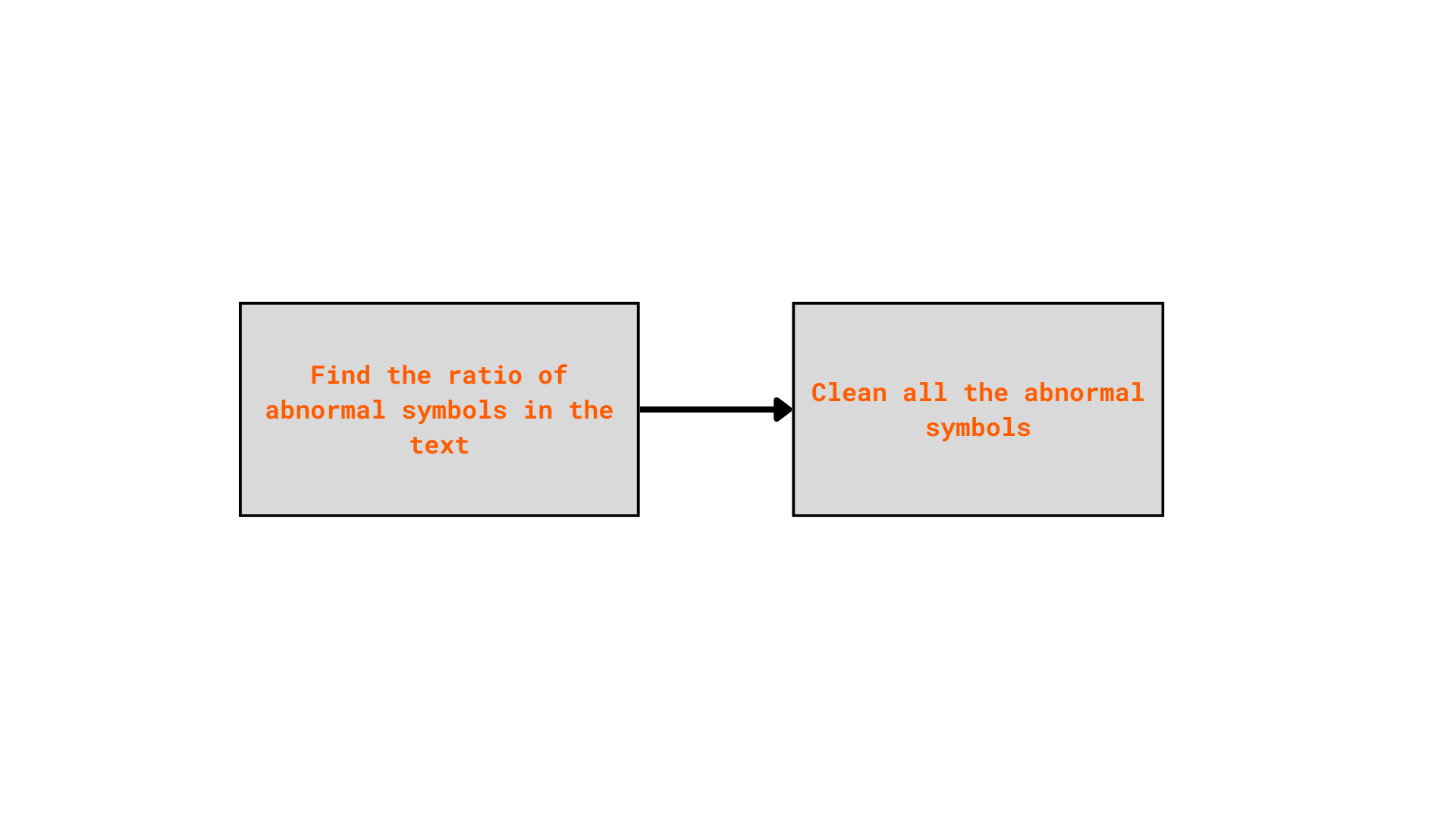
Step 02: Detect abnormal symbols in texts:
Certain symbols — such as #, ^, ~, -, and non-Unicode characters — do not
carry meaningful linguistic information and can negatively impact the quality of the
dataset.
However, there are multiple samples mainly contain these symbols, making them uninformative or even harmful for the language identification task.
| Language | Text |
|---|---|
| est | ”< 2A.4.1.4 type = “” S “” input = “” S “” Decision = N >” |
| est | ( slide No. 42 ) ¡¡£¹ºÐ¤Î»Ò¶¡¤Ç¤¹¤¬¡¢ÇòÆâ¾ã¤¬½Ð¤Æ¤ª¤ê¤Þ¤¹¡£¤³¤ÎÊý¤Ï²¿¥«·î¤«Á°¤Ë¤ä¤Ï¤ê¥¹¥Æ¥í¥¤¥É¤¬… |
To detect the abnormal symbols, I used unicodedata package to detect the character which is not ịn types: letter, mark, number.
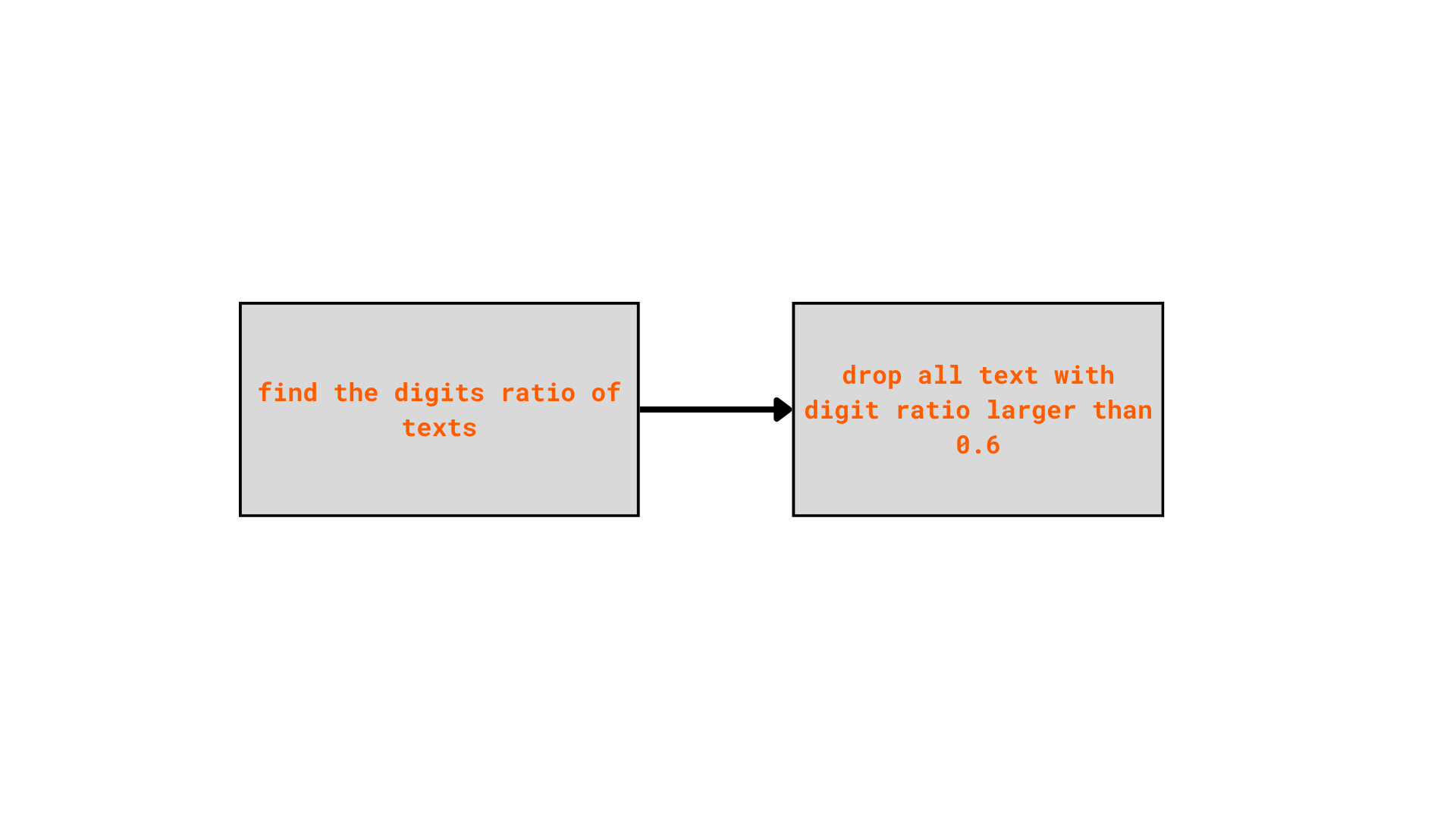
Step 03: Clean the text with high ratio of number
Texts consisting mostly numbers, can be math calculation, equation, or numeric tables, they should also be removed. Some examples in the current dataset:
| Language | Text |
|---|---|
| est | 79600000-0 kuni 79635000-4 (v.a 79611000-0, 79632000-3, 79633000-0), ja 98500000-8 kuni 98514000-9 |
| deu | 5 6 12 14 15 16 17 19 20 21 25 26 32 34 35 36 37 39 2 5 7 10 12 13 14 18 19 20 22 25 27 30 32 … |
| deu | 2755 2756 2757 2758 2759 2760 2761 2762 2763 2764 2765 2766 2767 2768 2769 2770 2771 2772 2773 27… |
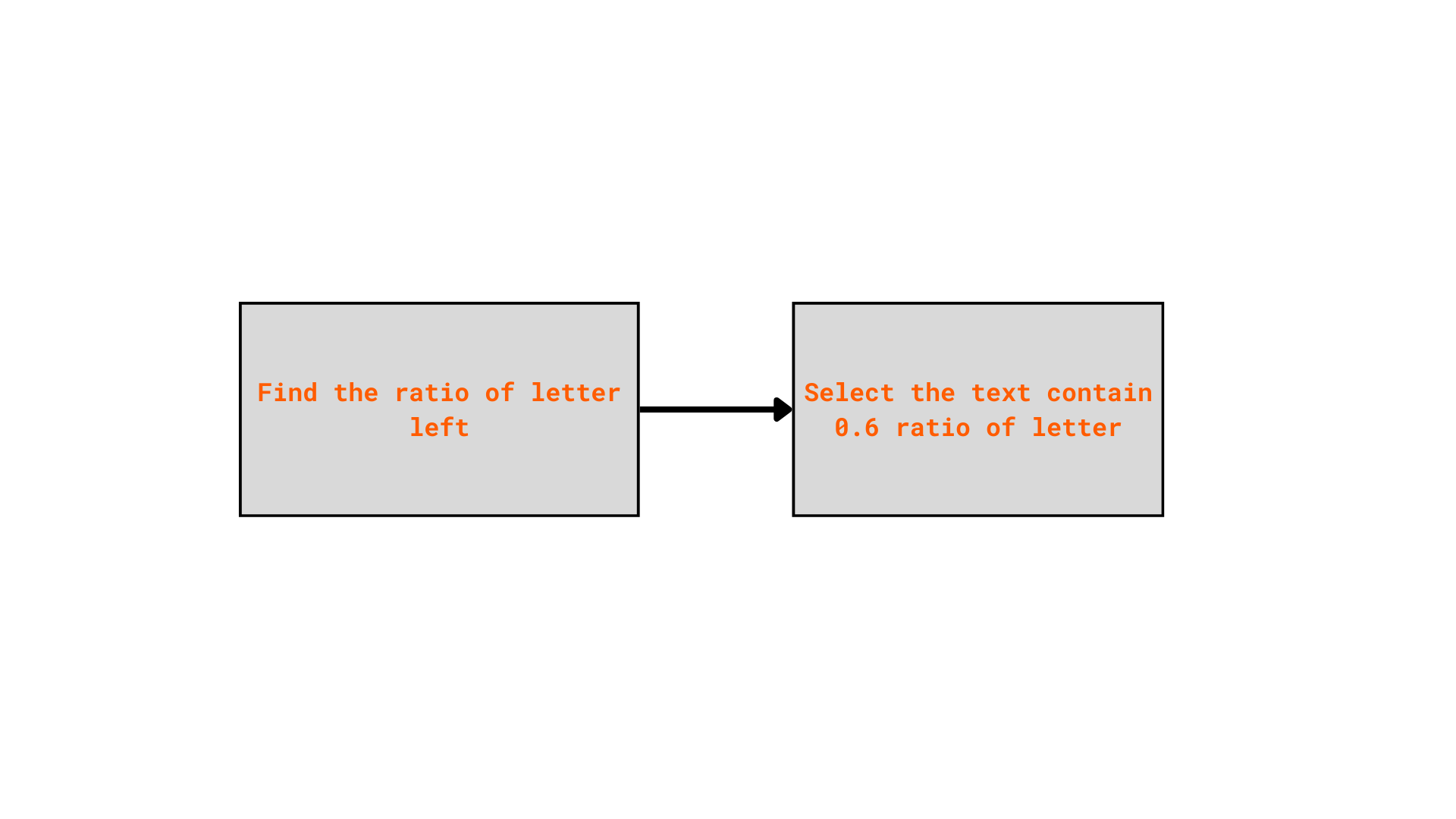
Step 04: Select mostly character texts
After multiple cleaning steps, some texts may become empty or just contain very little information left. There are lots of samples which is too short:
| text | source | lang | text_clean |
|---|---|---|---|
| ”< 5.1.1 type = “” S “” maxlength = “” 255 “” input = “” M “” decision = “” N “” > Kodukabjalised” | openlid | est | Kodukabjalised |
| peatati alates _ _ / _ _ / _ _ _ _ kuni _ _ / _ _ / _ _ _ _ | openlid | est | peatati alates kuni |
| == poopoos == poopoos!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!… | toxic_text | est | poopoos poopoos |
| ”< 3.1.11 type = “” N “” input = “” M “” SME “” > 5, i retsakten, og” | openlid | dan | 5, i retsakten, og |
Now we need to keep only texts that contain a sufficient proportion of informative characters.
The final dataset is stored in parquet files. The storage is significantly reduced compared with the tsv files in the previous step. The current dataset can be see here
Subsampling the data using SemHash and Cleanlab
The data now contains about 48,320,698 samples, which is too large to run the evaluation step on the current device. Therefore, the data must be downsampled, retaining only the highest-quality samples.
Here, I used SemHash, a lightweight, multimodal library, used for semantic deduplication, outlier filtering, and representative sample selection.
SemHash was applied separatedly to each language:
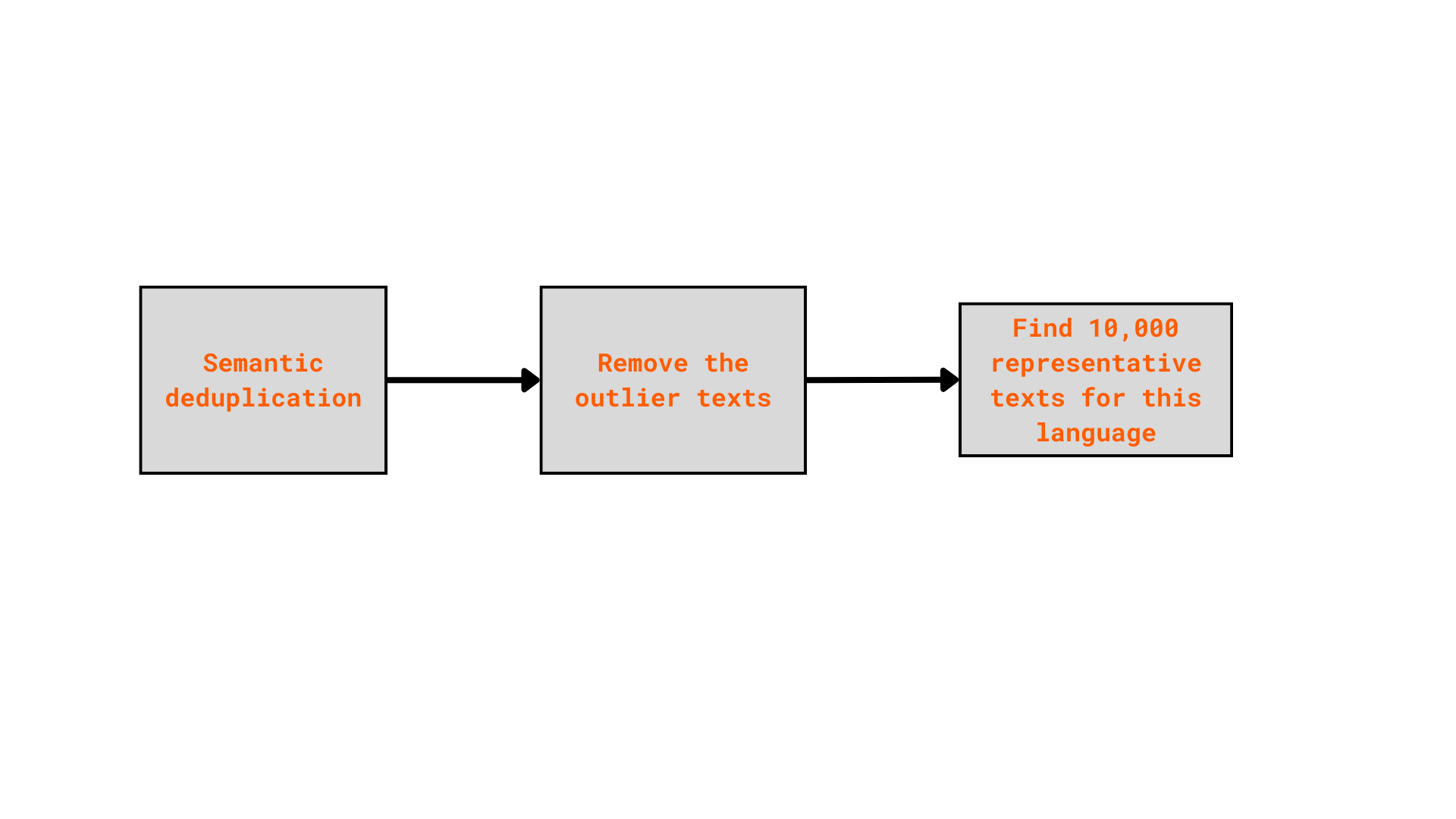
Finally, the data is stored in many parquet files, one per each language. For more details, visit this notebook
In a language dataset, an important issue is language misslabeling. The incorrect labeled samples can significantly affect the training process, and negativly impact the model performance.
To solve this problem, I used Cleanlab a library which works with any ML model by analyzing model outputs like predicted probabilities and feature embeddings to identify problems such as label errors, outliers, near duplicates, and other data quality issues.
In Cleanlab, there are two important elements:
- The embeder: Create the embedding vectors of the given text.
- Classifier: Trained from the data, to create the predicted language probabilities for a given text.
After trying with multiple setting of embedder and classifier, I have these main settings. The detailed implementation can be found in this notebook
| Embedder | Classifier | API |
|---|---|---|
| FastText | Logistic Regression | cleanlab.classification.CleanLearning |
| Transformer + FastText | XGB Classifier | cleanlab.classification.CleanLearning |
| FastText | Logistic Regression | cleanlab.filter.find_label_issues |
| Transformer | Logistic Regression | cleanlab.filter.find_label_issues |
Different settings will result in a different label-cleaned versions of dataset. From that, I ensembled all of them, using a simple strategy that a text, which will have a highly confident about the label quality, if it appear in all versions. The detailed implementation can be found in this notebook.
After all of these steps, I have a cleaned version of the dataset, containing about 1,5 million samples. And it still is not completely clean. 🥲🥲🥲
Task 03: Doing EDA for the collected dataset
In this section, I will discover the dataset. The detailed analysis on the dataset can be found in this notebook
Some key features about the dataset are:
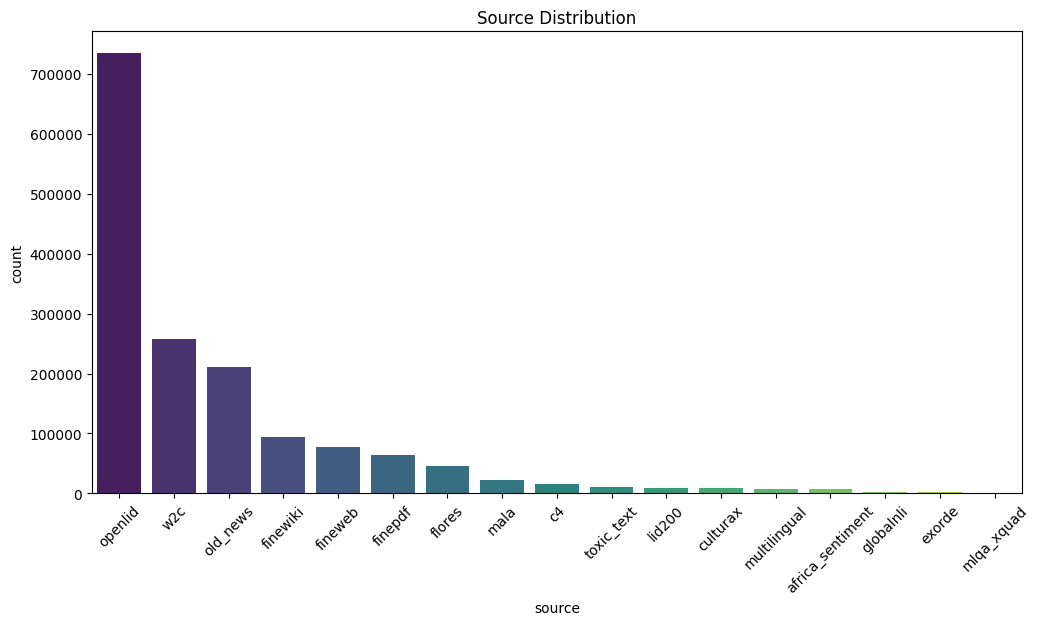
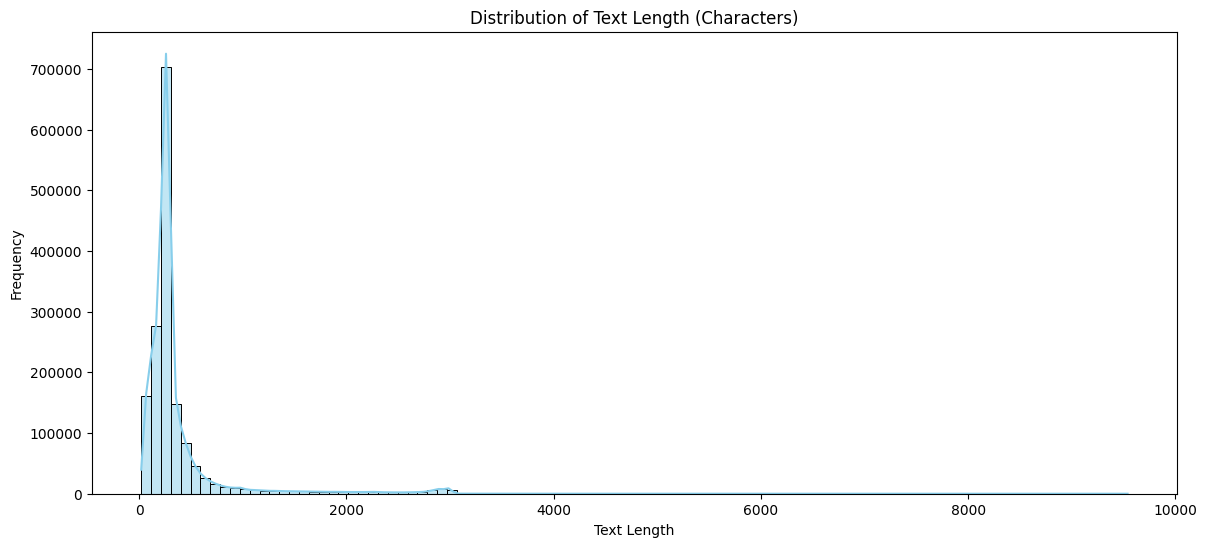
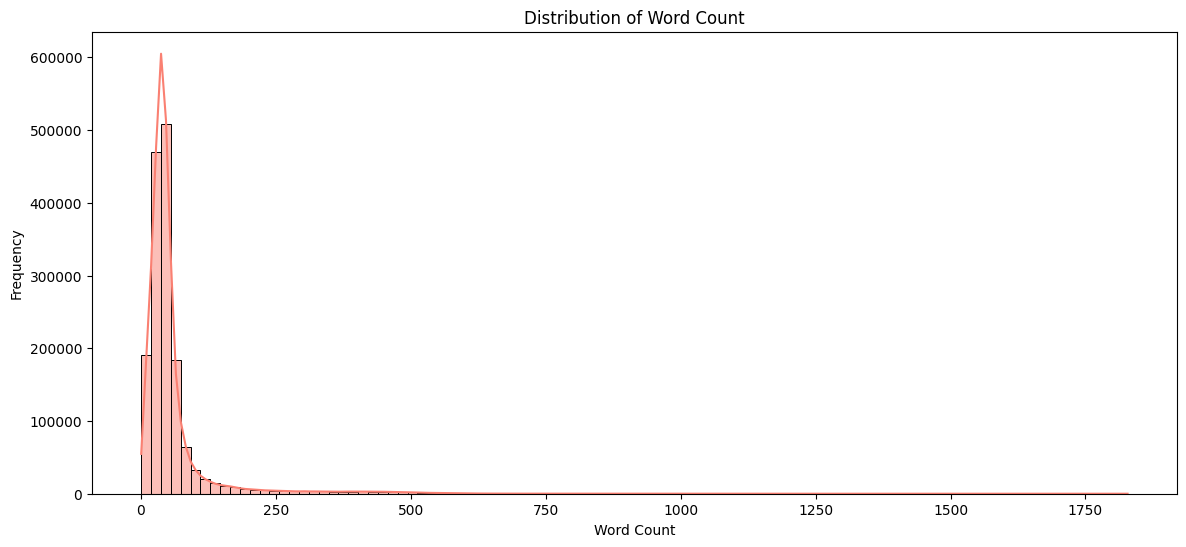
Task 04: Evaluate the cleaned dataset with models
Here is the list of model I evaluated, also consider the supporting language list for all these models:
- papluca/xlm-roberta-base-language-detection: 20 possible labels
- WordLlama Detect: 146 possible labels
- julien-c/fasttext-language-id: 175 possible labels
- NeuML/language-id: 175 possible labels
- laurievb/OpenLID-v2: 194 possible labels
- alexneakameni/language_detection: 195 possible labels
- facebook/fasttext-language-identification: 211 possible labels
- epfl-nlp/ConLID: 1869 possible labels
- cis-lmu/glotlid: 1873 possible labels
We can see the papluca model only supports a limited set of languages (20 languages),
while conlid and glotlid can support more than 1800 languages. Other models support
around 100–200 languages.
To ensure a fair evaluation between models, we consider three scenarios:
- Scenario 1: Evaluate all models, except
papluca, on an 83-language dataset (the overlap of supported languages across all other models). - Scenario 2: Evaluate all models, including
papluca, on a 17-language dataset. - Scenario 3: Evaluate only conlid and glotlid on a 1810-language dataset.
For each scenario, I evaluated each language separately, recording:
- The accuracy of each model per language
- The total inference time per language
- The inference time per sample per language
Additionally, I stored the detailed prediction results of all models for each sample, for future analysis.
The full evaluation code can be found in the notebooks: CPU evaluation and GPU evaluation
Task 05: Analyze the Evaluation Results
The detailed analysis can be found in this notebook.
Here, I will summarize some key insights:
1. Metrics
I evaluated all models using two metrics: accuracy and F1-macro score.

In Scenario 1, the evaluation was conducted on around 100 of the most popular languages. Among the evaluated models, Conlid and lmu_glotlid achieved the highest performance in both accuracy and F1 score. These models also have the widest language coverage, with more than 1800 languages evaluated in Scenario 3. However, this high performance was not consistently maintained across both scenarios. One possible reason is the evaluation data itself — many low-resource languages (~700 languages) have only one sample, which can lead to unfair or unstable results.
In Scenario 2, where the evaluation focused on the top 17 most popular languages, the papluca model — which supports only 20 languages — achieved the highest performance. This suggests the model is primarily trained on popular languages and performs well in simpler, high-resource settings.
Additionally, the neuml_langid model showed very poor performance in Scenario 1. Although its performance improved in Scenario 2, it still remained significantly lower than the other models.
2. Memory Usage
Memory usage is a key factor when selecting a language identification model. Ideally, we want a model that is lightweight, yet achieves strong performance and fits practical deployment requirements.
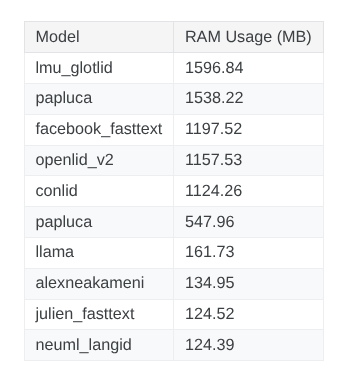
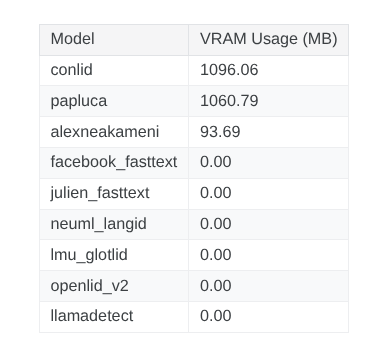
Look at the RAM usage, we observe that evaluated models requires from hundreds to thousands of megabytes. Only a few transformer-based model can support the GPU execution. Therefore, most evaluations are performed on the CPU. This als reflects a trend in model development nowadays, where models are become more lightweight and optimized for CPU-based inference.
In more detail, I used the pareto plot to show the relation between memory usage and the model accuracy. The analysis focuses on Scenario 01 and Scenario 02, where multiple models are compared under the same evaluation settings.
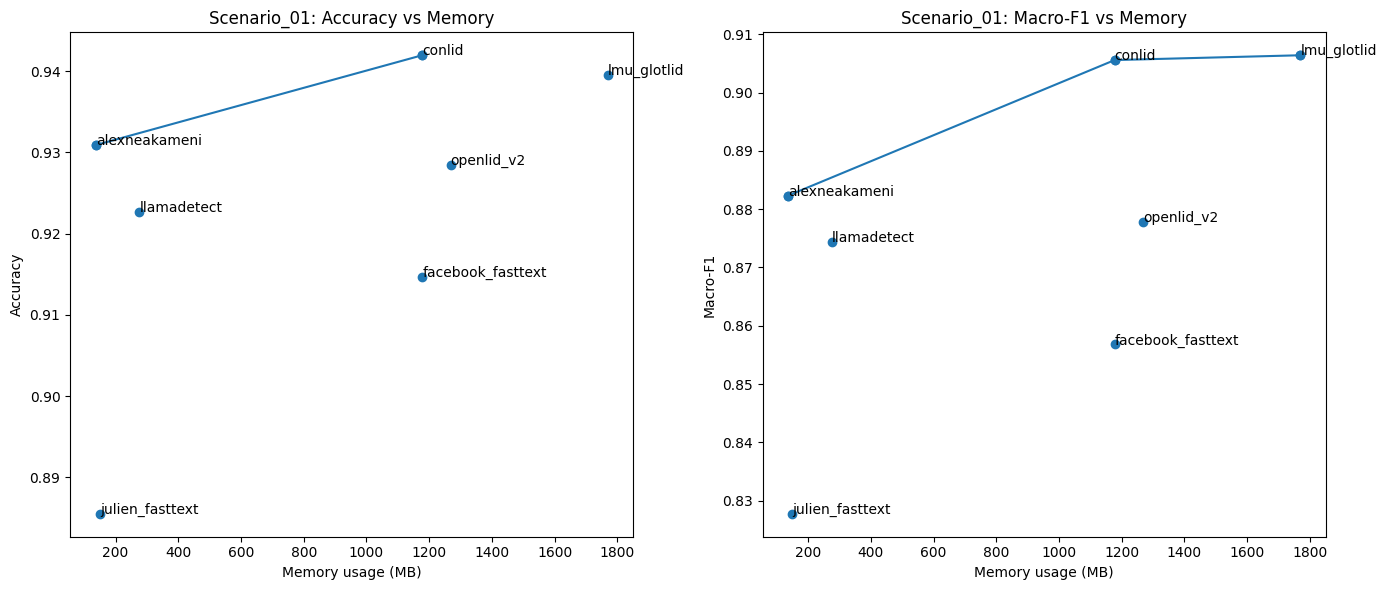
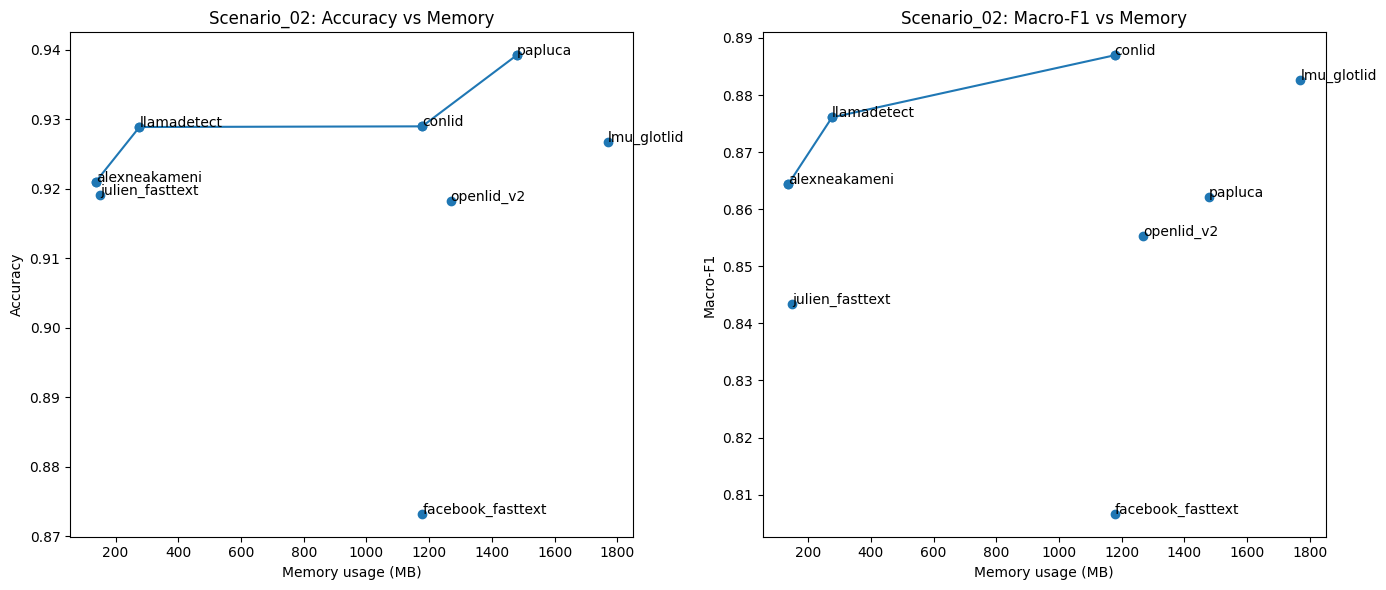
From the results, Conlid achieves the highest accuracy while using an acceptable amount of memory. Additionally, alexneakameni is the most lightweight model, with competitive accuracy. llamadetect also offers a strong balance between low memory consumption and performance.
3. Throughput
Throughput is measured as the number of samples a model can process per second. This is an important factor for many real-world applications that require a fast and accurate language identification module.
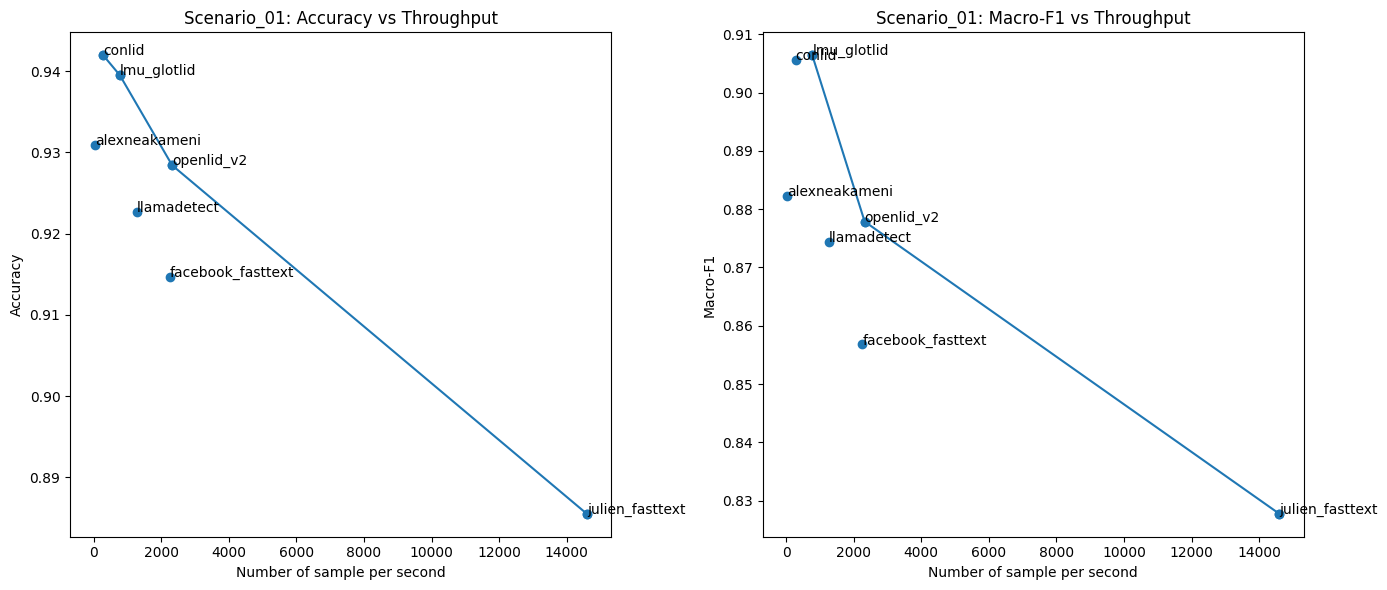
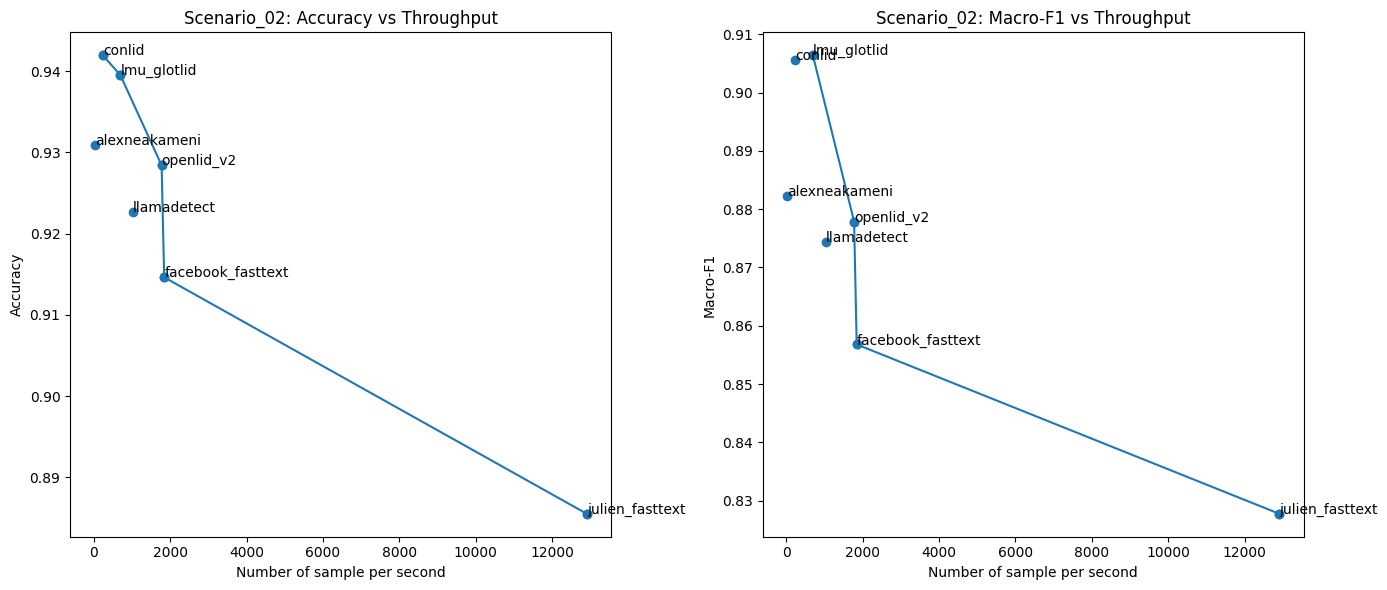
In terms of throughput, Conlid, despite achieving the highest accuracy, is the slowest model. This suggests that Conlid is best suited for scenarios where accuracy is the top priority, rather than memory efficiency or inference speed.
The julien_fasttext model, which has very low memory consumption, achieves the highest throughput. However, its overall accuracy is not particularly strong. Therefore, it is a suitable option for tasks with strict speed and resource constraints.
Additionally, the llamadetect model offers a well-balanced trade-off across accuracy, memory usage, and throughput, making it a strong candidate for a wide range of practical applications.
Conclusion
Through this project, I gained valuable knowledge about current language identification
methods and hands-on experience working in the NLP field. In next part, we will explore about a state-of-the-art model: WorldLlama Detect