Language Identification Model Evaluation - Part 02 - Replicate WordLlama Detect Model
Learning about the WorldLamma Detect model and attempt to replicate its architecture by experimenting with alternative embedding backbones to improve performance
Project period: Sep 2025 - Mar 2026
Project team:
- Mr.Hoan Nguyen (Superviser)
- Huynh Cao Khoi
Role:
- Data Collecting
- Data Preprocessing
- Exploratory Data Analysis (EDA)
- Model Evaluation
- Evaluation result analysis
Tools:
- Hugging Face API, Polars, sentence_splitter, pyspark,unicodedata, semhash, cleanlab, Matplotlib, Seaborn, pytorch
Overview
In the previous part, we consider that the llamadetect model offers a well-balanced trade-off across accuracy, memory usage, and throughput. In this section, we will deeply dive into its structure.
WordLlama Detect is a WordLlama-based library specifically designed for language identification. It supports 148 languages and is built for high accuracy with fast, CPU-only inference using NumPy — no GPU required.
Key highlights:
- Model size: only 13MB
- Throughput: 70,000 – 100,000 texts/second on a single thread
- Language coverage: 148 languages
For more details, we can visit the office blog post
The overall structure of WorldLLamma is look like this:
Input Text
│
▼
┌────────────────┐
│ Tokenize │
└────────────────┘
│
▼
Token IDs: [t₁, t₂, ..., tₙ]
│
▼
┌──────────────────────────┐
│ Lookup Embeddings │ ← Gemma 3 frozen embeddings
└──────────────────────────┘
│
▼
Embeddings: [e₁, e₂, ..., eₙ] (each eᵢ ∈ ℝᵈ)
│
▼
┌──────────────────────────┐
│ Project + Weight │ ← Learned: W, b, {wᵢ}
└──────────────────────────┘
│ ℓᵢ = wᵢ · (W·eᵢ + b)
▼
Logits: [ℓ₁, ℓ₂, ..., ℓₙ] (each ℓᵢ ∈ ℝᴸ)
│
▼
┌──────────────────────────┐
│ Log-Sum-Exp Pool │
└──────────────────────────┘
│ z = log[Σᵢ exp(ℓᵢ)]
▼
Aggregated Logits: z ∈ ℝᴸ
│
▼
┌──────────────────────────┐
│ Softmax │
└──────────────────────────┘
│
▼
Language Probabilities
The most important component of LlamaDetect is the embedding lookup step — a rich, high-quality text embedding provides a strong input representation, directly impacting the model’s identification accuracy.
This naturally raises an interesting question:
If we replace Gemma 3 with a stronger embedding model, can we boost LlamaDetect’s performance?
The goal of this experiment is to find an alternative embedding backbone that is either faster or more accurate than the current Gemma 3-based WordLlama.
We explored two main approaches:
- Surveying multilingual LLMs and embedding models — collecting a set of candidate models that support multilingual text representation as potential replacements for Gemma 3.
- Exploring alternative training strategies — investigating whether changes to the training process itself could improve performance independently of the backbone.
1. Surveying multilingual LLMs and embedding models
For the language identification task, the quality of a model is closely tied to the diversity of its training data (the data mixture). The wider the range of languages and domains a model covers, the more expressive and discriminative its embeddings will be. Therefore, language and domain coverage was our primary criterion when surveying candidate models.
The full list of model is here
Retraining the LlamaDetect Model
Firstly, I firstly check the availability of the code provided in WordLlama Detect’s github, while running the provided code, I encountered serveral challenges:
-
Missing data preparation code: The repository does not include the data preparation pipeline, so I had to reimplement it from scratch.
-
CUDA compatibility issues: With the limitation of device, I used Kaggle GPU to train to model. However, the default configuration requires a modern CUDA device, which is incompatible with Kaggle’s GPU environment. I had to set up a custom environment and modify the package requirements accordingly.
The training process is shown in this notebook
During training, I discovered several key insights about the model:
- High VRAM requirement: the training process requires more than 16GB of VRAM, which exceeds Kaggle’s GPU capacity. I had to adjust the training hyperparameters to fit within the available resources.
- Sensitivity to hyperparameters — even small changes in hyperparameters led to noticeable differences in model performance, making tuning particularly challenging.
Ultimately, while I successfully trained the model, it was unable to match the performance of the author’s released model. This is primarily due to hardware limitations — we were unable to replicate the full training configuration reported in the original work.
Training Worldllama Detect with other LLMs or embedding model
After make sure we can use the code, I replace the Gemma3 model with some models in the survey:
| Model | Num support language | Num trained lang | Accuracy | F1-score |
| Baseline - Gemma 3 27b | 148 | 148 | 0.916073 | 0.917110 |
| Mala 500 | 534 | 169 | 0.8438 | 0.8423 |
| mmbert | 1834 | 190 | 0.732565 | 0.737130 |
| Apertus 70b | 1812 | 190 | 0.678821 | 0.676668 |
| Qwen 3 | 122 | 111 | 0.840024 | 0.839785 |
| Gemma 300m | 148 | 148 | 0.913774 | 0.913658 |
| bge m3 | 31 | 25 | 0.997031 | 0.997030 |
| babel | 25 | 22 | 0.994620 | 0.994624 |
| eurobert | 15 | 13 | 0.989970 | 0.989981 |
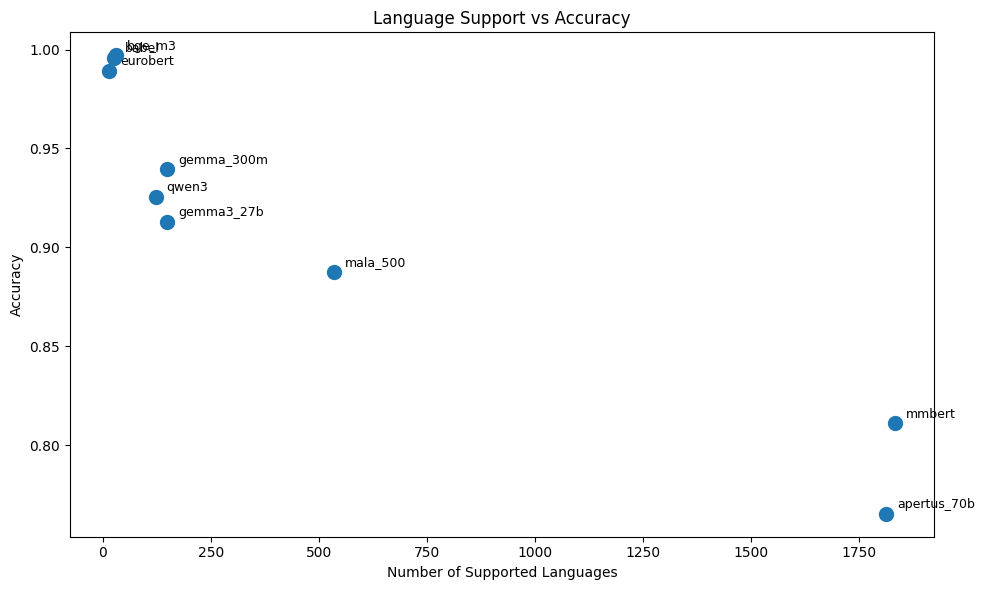
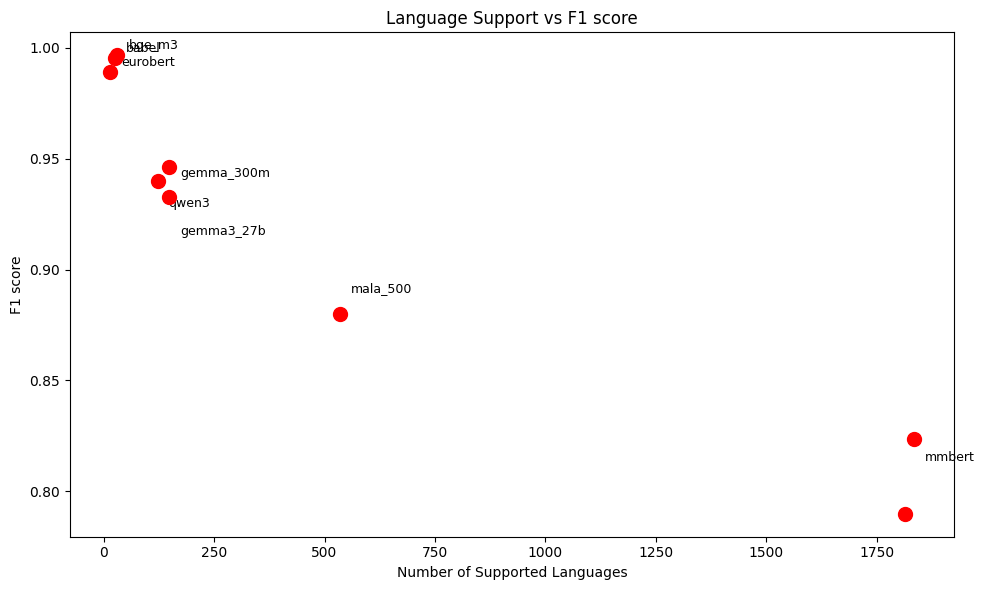
There is a clear negative correlation:
- Models with very large language coverage (1000+) like
mmbert(1834) orapertus_70b(1813) have the lowest performance. - Models with medium coverage (100–500) like
mala_500(534),qwen3(122) orgemma family(148) have a balance performance. - Models with small coverage (≤30) like
bge_m3(31),babel(25),eurobert(15) have a near-perfect performance
This trend can related to a difficulty that multilingual representation learning becomes harder as languages increase, while we have more language, it become more difficult to align everything into a limited embedding space.
Beside that, the large number of languages create the class imbalance, there will be more sparse or low quality data, model will focus on dominant languages and pull the performance to the average.
As the language support range is different between models, I also find the overall metric of the 10 common languages across models:
| Model | Accuracy | F1-macro |
|---|---|---|
| apertus_70b | 0.7653 | 0.7898 |
| mmbert | 0.8111 | 0.8237 |
| mala_500 | 0.8876 | 0.8801 |
| gemma3_27b | 0.9129 | 0.9329 |
| qwen3 | 0.9256 | 0.9398 |
| gemma_300m | 0.9394 | 0.9464 |
| eurobert | 0.9894 | 0.9892 |
| babel | 0.9957 | 0.9952 |
| bge_m3 | 0.9971 | 0.9966 |
Across almost every model, performance improves when we restricted to the 10 common languages, with different sizr of improvement:
- Strong improvement:
-
Apertus 70B: Accuracy:0.6788 -> 0.7653 (+0.0865)F1: 0.6767 -> 0.7898 (+0.1131) -
mmBERT: Accuracy:0.7326 -> 0.8111 (+0.0785)F1: 0.7371 -> 0.8237 (+0.0866)
-
=> These models - which have the largest language coverage - also have the most significant improment. It shows that these models really have the struggle with broader language coverage and benefit a lot when restricted.
- Moderate improvement:
Mala 500: Accuracy:0.8438 -> 0.8876 (+0.0438)Qwen 3: Accuracy:0.8400 -> 0.9256 (+0.0856)
=> Qwen shows large gain, meaning it performs much better on high-resource languages than low-resource ones.
- Small improvement (good multilingual robustness)
Gemma 3 27B: Accuracy:0.9161 -> 0.9129 (slight drop)Gemma 300M: Accuracy:0.9138 -> 0.9394 (+0.0256)
=> These models are already strong across many languages, so restricting doesn’t change much.
- Almost no change (highly consistent)
bge-m3: Accuracy:0.9970 -> 0.9971babel: Accuracy:0.9946 -> 0.9957eurobert: Accuracy:0.9900 -> 0.9894
=> These models are trained on narrow but well-covered language sets, so the performance does not changed.
| Model A | Model B | Common Langs | Acc A | Acc B | F1 A | F1 B |
|---|---|---|---|---|---|---|
| gemma3_27b | apertus_70b | 144 | 0.9175 | 0.7247 | 0.9161 | 0.7278 |
| gemma3_27b | gemma_300m | 146 | 0.9182 | 0.9160 | 0.9168 | 0.9152 |
| gemma3_27b | mala_500 | 132 | 0.9145 | 0.8956 | 0.9133 | 0.8823 |
| gemma3_27b | mmbert | 144 | 0.9174 | 0.8038 | 0.9161 | 0.7971 |
| gemma3_27b | qwen3 | 96 | 0.9254 | 0.8803 | 0.9206 | 0.8667 |
| gemma3_27b | bge_m3 | 25 | 0.9293 | 0.9970 | 0.9303 | 0.9970 |
| gemma3_27b | babel | 22 | 0.9253 | 0.9942 | 0.9290 | 0.9942 |
| gemma3_27b | eurobert | 13 | 0.9202 | 0.9900 | 0.9365 | 0.9900 |
The analysis code can be found in this notebook
So after replace Gemma 3 in the embeding component with other models, we cannot find a suitable candidate with can boost the performance.
Now, we will try to use some ensemble strategy in model training.
Ensemble strategy 01: Stacking
Training data (740k samples)
│
▼
┌───────────────────────────────────┐
│ Phase 1: Base Models │
│ │
│ ┌─────────────┐ ┌─────────────┐ │
│ │LID Model 01 │ │ LID Model 02│ │
│ └──────┬──────┘ └──────┬──────┘ │
└─────────┼────────────────┼────────┘
│ train each │
│ independently │
▼ ▼
lid_models[0] lid_models[1]
│ │
└───────┬────────┘
│
▼
collect_preds() → X: (N, 2*148) = (N, 296)
model1 logits model2 logits
(N, 148) cat (N, 148)
└────────┬──────────┘
▼
(N, 296)
│
Linear(296 → 148) ← 296*148 = 43,808 params trained
│
▼
(N, 148) → CrossEntropy(y)
| Pair | Num Languages | Accuracy | F1 Macro | Metric per Base Model |
|---|---|---|---|---|
| gemma3_27b + gemma_300m | 148 | 0.9307 | 0.9303 | gemma3_27b: Acc: 0.9147, F1: 0.9149 gemma_300m: Acc: 0.9087, F1: 0.9078 |
| mala_500 + gemma_300m | 131 | 0.9584 | 0.9592 | mala_500: Acc: 0.9372, F1: 0.9394 gemma_300m: Acc: 0.9075, F1: 0.9071 |
Ensemble strategy 02: Weighted averaging
Training data (740k samples)
│
▼
┌───────────────────────────────────┐
│ Phase 1: Base Models │
│ │
│ ┌─────────────┐ ┌─────────────┐ │
│ │LID Model 01 │ │ LID Model 02│ │
│ └──────┬──────┘ └──────┬──────┘ │
└─────────┼────────────────┼────────┘
│ train each │
│ independently │
▼ ▼
lid_models[0] lid_models[1]
│ │
└───────┬────────┘
│
▼
collect_preds() → X: (N, 2, 148)
model1 logits model2 logits
(N, 148) (N, 148)
│ │
w1 (scalar) w2 (scalar) ← only 2 params trained
│ │
└────────┬──────────┘
▼
w1*L1 + w2*L2 softmax(w) ensures w1+w2=1
│
▼
(N, 148) → CrossEntropy(y)
| Pair | Num Languages | Accuracy | F1 Macro | Metric per Base Model |
|---|---|---|---|---|
| gemma3_27b + gemma_300m | 148 | 0.9313 | 0.9313 | gemma3_27b: Acc: 0.9147, F1: 0.9149 gemma_300m: Acc: 0.9087, F1: 0.9078 |
From the results, we can see that ensemble methods can boost the model’s performance significantly. The tradeoff, however, is a more complex training pipeline, we need to train two separate base models independently before combining them in the meta/weighted fusion stage.
Matryoshka Representation Learning
Matryoshka Representation Learning is a way to make the model learn good representation in different size
Input token_ids (B, T)
│
▼
embeddings[token_ids] # (B, T, hidden_dim)
│
token_weights *
│
dropout
│
pool # (B, hidden_dim)
│
┌────┴─────────────────────────────────────┐
│ slice to each dim │
▼ ▼ ▼ ▼ ▼
x[:,:64] x[:,:128] x[:,:256] x[:,:512] x[:,:5376]
│ │ │ │ │
Linear Linear Linear Linear Linear
(64→148) (128→148) (256→148) (512→148) (5376→148)
│ │ │ │ │
logits_0 logits_1 logits_2 logits_3 logits_4
│ │ │ │ │
└────┬────┴─────────┴─────────┘ │
│ │
FocalLoss x4 FocalLoss x2 (weighted higher)
│ │
└──────────────┬───────────────────────┘
│
total_loss / 6
│
backward()
| Model | Accuracy | F1 Macro | F1 Weighted |
|---|---|---|---|
| gemma3_27b | 0.2734 | 0.2521 | 0.2503 |
| gemma3_27b @ dim=128 | 0.2050 | 0.1902 | 0.1918 |
| gemma3_27b @ dim=64 | 0.1650 | 0.1481 | 0.1492 |
On the other hand, the MRL (Matryoshka Representation Learning) approach did not perform as expected. After investigation, we realize that MRL requires the embeddings to be trained end-to-end with the MRL objective from the start, so the model can learn to concentrate the most discriminative information into the earliest dimensions. In our case:
- The embeddings are static and pre-trained (from Gemma)
- We only train the classifier head, not the embeddings themselves
This means the early dimensions carry no more information than any other slice, making the smaller MRL heads much weaker than the full-dim head.
Conclusion
Although we did not achieve a significant improvement over the baseline WordLlama Detect, this project provided valuable insights into ensemble strategies and the limitations of applying MRL to static embedding models.
Special thanks to my supervisor, Hoan Nguyen, for his thoughtful and practical advice throughout this project.